아스키코드
사람의 언어를 컴퓨터 언어로 변환하기 위한 중간 기호 표
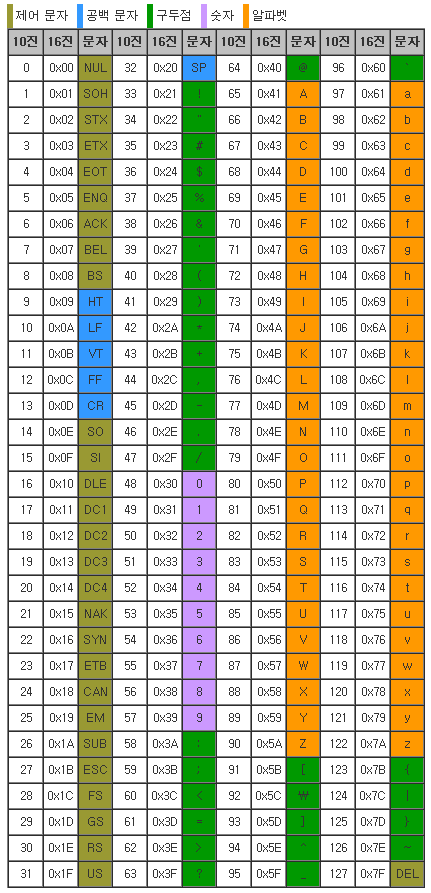
(7비트 부호로 128개의 숫자가 알파벳, 숫자, 특수문자, 제어문자 포함됨)
아스키코드 왜 필요해? 사람언어 -> 컴퓨터 언어 바로 바꾸면 안돼?!
'통신'하기 위해서는 기준이 필요합니다.
만약 아스키코드가 없다면 무슨 일이 벌어질까요?
철수는 A를 0001(컴퓨터 언어 이진수)로 쓰고 영희는 A를 0010으로 사용한다고 합시다.
그럼 철수가 영희에게 AAA 라는 메시지를 보내면 영희가 받은 메시지는 0001/0001/0001 입니다.
영희의 A는 0010이였죠..? 그럼 당연히 이상한 값으로 해석(디코딩) 되거나 글자가 깨져버립니다.
유니코드
아스키코드의 확장판, 영어만 포함하지 말고 다른 나라 언어도 포함시켜줘..
이제부터는 다른 나라 언어들도 포함시켜서 기준을 만들었습니다.
글자와 코드가 1:1 매핑되어 있으며 운영체제나 프로그램 언어에 관계없이 문자마다 고유한 코드 값을 제공합니다.
이제 언어와 상관 없이 모든 문자를 16비트로 표현하여 최대 65,536자 까지 표현할 수 있게 되었습니다. ☺️

인코딩이란?
인코딩: 어떤 기준표를 이용해서 문자를 다른 문자로 바꾸는 것입니다.(이 글에서는 사람 언어 -> 컴퓨터 언어)
국제적으로 '어떤 기준표'를 사용해서 '어떻게' 인코딩 할 것인지 그 방식들이 이미 있습니다.
위에서 저희는 아스키코드, 유니코드라는 대표적인 기준표에 대해서 살펴봤습니다.
그런데 저희는 컴퓨터에 '어떻게' 저장할건데? 도 필요합니다. '어떻게' 라는 것은 무엇을 말하는 걸까요?
예를 하나 들어보겠습니다.
우선 유니코드를 기준으로 하는 몇가지 인코딩 방식들을 살펴보겠습니다.
유니코드 인코딩 방식
- UTF-8 : 8비트로 1개의 Index를 표현하겠다. (리틀엔디안 빅엔디안 신경 안써서 편함)
- UTF-16 LE : 16비트로 1개의 Index를 표현하겠다. (메모리 저장 방향 : 리틀 엔디안)
- UTF-16 BE : 16비트로 1개의 Index를 표현하겠다. (메모리 저장 방향 : 빅 엔디안)
- UTF-32 : 32비트로 1개의 Index를 표현하겠다.
이것들은 모두 유니코드를 기준으로 하는 인코딩 방식입니다.
설명란에는 각각 무슨 차이점이 있는지 적어놨는데요. Index란 유니코드표에서 'A'라는 글자가 적혀져 있는 위치입니다.
Index를 Code Point 혹은 Code Unit라 부르기도 합니다.
'A'라는 글자는 0x0041이라는 Index를 가진다.
'a'라는 글자는 0x0061이라는 Index를 가진다.
'가 '라는 글자는 0xac00이라는 Index를 가진다.유니코드표의 0x0041이라는 인덱스로 가면 A 라는 글자가 있습니다.
밑에 링크타고 가서 0x0041 검색해보면 해당 글자가 있는 유니코드 블록을 pdf로 보여줍니다.
http://www.unicode.org/charts/
Unicode 14.0 Character Code Charts
Unicode 14.0 Character Code Charts Scripts | Symbols & Punctuation | Name Index Find chart by hex code: Help Conventions Terms of Use Notational Systems Braille Patterns Musical Symbols Ancient Greek Musical Nota
www.unicode.org
즉, 같은 유니코드를 사용하더라도 얼만큼의 메모리 영역을 잡고 어느 방향으로 쓸 지에 대해서도 다르게 하여 인코딩 방식을 나눌 수 있습니다. 후 이게 바로 '어떻게' 군요..
아 참고로 UTF-8과 UTF-16은 호환이 안됩니다.
인코딩 방식의 다양한 종류
UTF-8
유니코드의 대표적인 가변 인코딩 방식 입니다.
가변 인코딩이란 글자마다 byte 길이가 다르다는 뜻입니다. 영어는 1바이트, 한글은 3바이트로 인코딩 하게 됩니다.
그런데 'abc' 이러면 3바이트죠. '가'도 3바이트죠. 그래서 이것을 구분하기 위해 첫 바이트에 표식을 넣습니다.

또한 1바이트 영역은 아스키코드와 하위 호환성을 가집니다. 아스키 코드의 0~127까지는 UTF-8로 완전히 동일하게 기록됩니다.
UTF-16
유니코드의 가변 인코딩 방식으로 영어와 한글 모두 2byte로 표현 할 수 있습니다.
아스키코드와 호환성은 없습니다.
EUC-KR, CP949
EUCKR코드표를 기준으로 인코딩합니다.
EUCKR 코드표 : https://icodebroker.tistory.com/7077
EUC-KR은 우리나라에서 만든 인코딩 방식 입니다.
오래전부터 사용하던 인코딩 방식이고 한글을 2바이트로 나타낼 수 있습니다.
그러다가 EUC-KR에서 표현할 수 없는 한글이 있어 마이크로소프트에서 CP949를 사용 하기 시작했습니다.
당연히 MS사니까 윈도우에서 주로 쓰이는 인코딩 입니다.
지금은 잘 안쓰고 UTF-8을 사용하는 편입니다. 국제적인 유니코드 good.
유니코드의 정규화
Mac에서 window로 한글 파일명 보내니까 'ㅍㅏㅇㅣㄹ.txt ' 깨지네.. 아니~~~~ 기준 만들고 인코딩했잖아! 또 뭔데!
원인은 바로 이것 떄문입니다.
- '각'이라는 문자를 컴퓨터가 받았을 때 이것을 ㄱ + ㅏ + ㄱ 으로 처리할 지? (유니코드에 한글 자모, '각' 다 있음)
- '각'이라는 문자를 그대로 '각'으로 처리할 지?
위 처럼 조합해서 같은 문자가 될 수 있는 경우 하나로 통합시켜주는 정규화 작업을 해야 합니다.
정규화 방식의 대표적인 2가지만 보겠습니다.
| NFC(Normalization Form Composition) | NFD(Normalization Form DeComposition) |
| 모든 음절을 Canonical Decomposition(정준 분해) 후 Canonical Composition(정준 결합) 하는 방식 | 모든 음절을 Canonical Decomposition(정준 분해)하여 한글 자모 코드를 이용하여 저장하는 방식 |
오 그러니까 ㄱ + ㅏ + ㄱ 으로 처리하는게 NFD 이고
'각' 으로 처리하는게 NFC 라는 거군요.
문제는 OS별로 지원하는 정규화 방식이 다르다는 것이죠.
window는 NFC를 지원합니다.
mac은 한글을 저장할 때 NFD 방식을 사용합니다. 그러나 NFC 방식도 지원합니다.
그래서 Window에서 mac으로 한글로 된 파일을 넘기면 한글 자모 분리 현상이 일어나지 않지만
Mac에서 Window로 옮기면 NFD 방식인 한글 자모로 저장하기 때문에 ㄱ + ㅏ + ㄱ 이 넘어가는데
Window는 NFD를 지원안하니까 ㄱ + ㅏ + ㄱ 을 하나로 합치지 못하고 한글 자모가 깨지는 현상이 발생하게 되는 것 입니다.
정리하기
- 아스키코드와 유니코드는 사람 언어를 컴퓨터 언어로 만들기 위한 기준이 되는 표이다.
- 글자가 깨지지 않고 서로 잘 통신하려면 인코딩 방식을 맞춰야 한다.
- 문자열 정규식 쓸 때 : Swift의 NSRegularexpression은 NFC로 정규화 해야 걸러진다. NSPredicate는 NFD도 걸러줌. 이건 내가 하면서 알게된건데.. 잊지 않기 위해 적어봄.
참고했던 글들
'IOS Swift' 카테고리의 다른 글
| iOS - 이벤트 처리 흐름 (0) | 2022.02.11 |
|---|---|
| App Store 개발자 등록하기 (0) | 2021.12.20 |
| 앱 실행 흐름 (1) | 2021.10.07 |
| 비디오 & 오디오 형식 변환을 위한 사전지식 (0) | 2021.10.04 |
| 멀티윈도우 지원하는 앱 만들기 - iOS (8) | 2021.09.28 |



